
One of the goals of the CinCan project is to provide tools that automate the repetitive tasks of malware analysis using practices familiar from continuous integration to enable rapid creation, augmentation, correlation and sharing of analysis and threat intelligence. Using Docker containers, we have portable tools, which can be conveniently configured for use in designated toolchains.
In order to test our Dockerized PDF analysis tools, we created a “malicious” PDF document using Metasploit. The document automatically runs an executable when opened. Let’s see what we discovered using these tools.
PDFID
At first, we used a tool by Didier Stevens, PDFID, with the triage plugin. The plugin scores samples as 1.0 (likely malicious) or 0.00 (clean), and sometimes something in between. The file sample.pdf is located in /samples, so, the Docker command to run is:
$ docker run --rm -v /samples:/samples cincan/pdfid /samples/sample.pdf -p plugin_triage
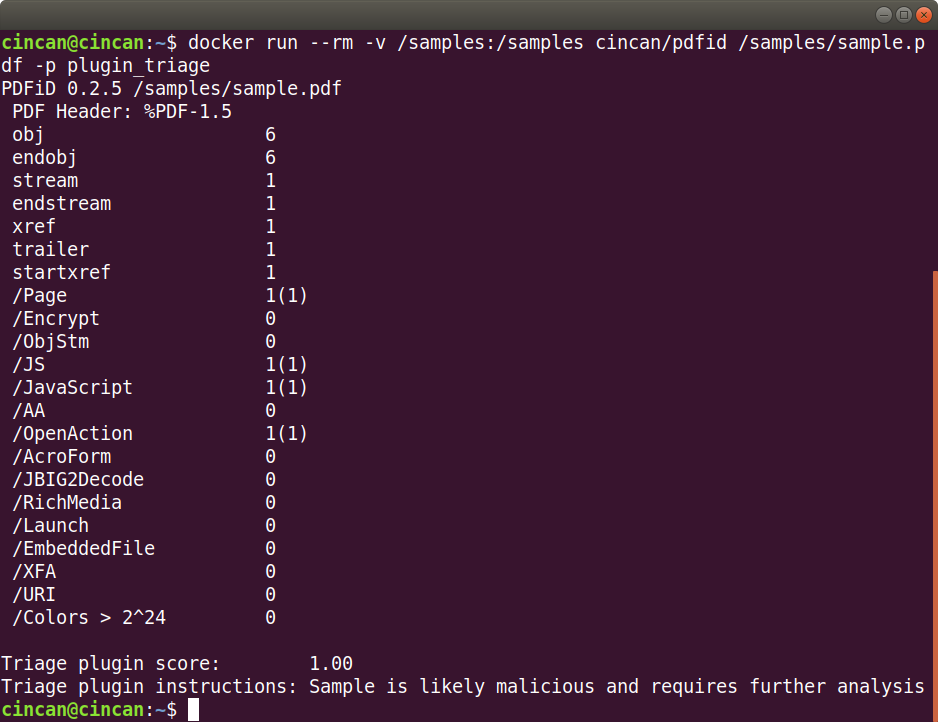
As we can see from the output, the PDF contains suspicious elements such as JavaScript and an OpenAction. The triage plugin gives a score of 1.00: likely malicious.
PDFExaminer
We also wanted to see what results PDFExaminer gives for our PDF. PDF Examiner is a free online scanner, which also has an API. To send in the sample, we ran the cincan/pdfexaminer image. In addition to this summary of results, PDFExaminer is also able to output several different formats like XML and JSON.
$ docker run --rm -v /samples:/samples cincan/pdfexaminer /samples/sample.pdf summary
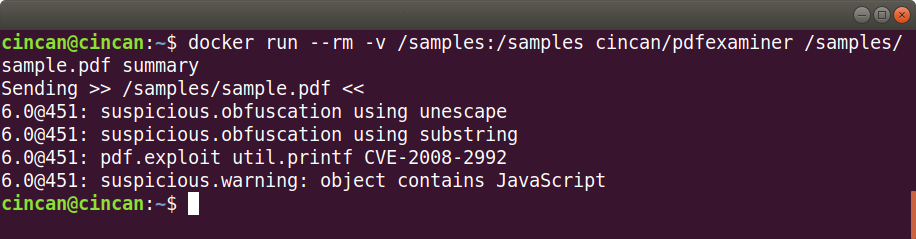
The PDFExaminer considers the sample malicious as well, as it contains obfuscation and JavaScript. It also reveals a potential exploit using util.printf, which may able an attacker to execute arbitrary code.
Jsunpack-n
Jsunpack-n is a tool that emulates browser functionality. It can be used to analyse URLs, and to detect possible exploits aimed at browsers or browser plug-ins, but it also has the ability to scan PDFs, unpack JavaScript and analyse pcap. In this particular case we use it to analyse the PDF document:
$ docker run --rm -v /samples:/samples cincan/jsunpack-n /samples/sample.pdf -d /samples/output
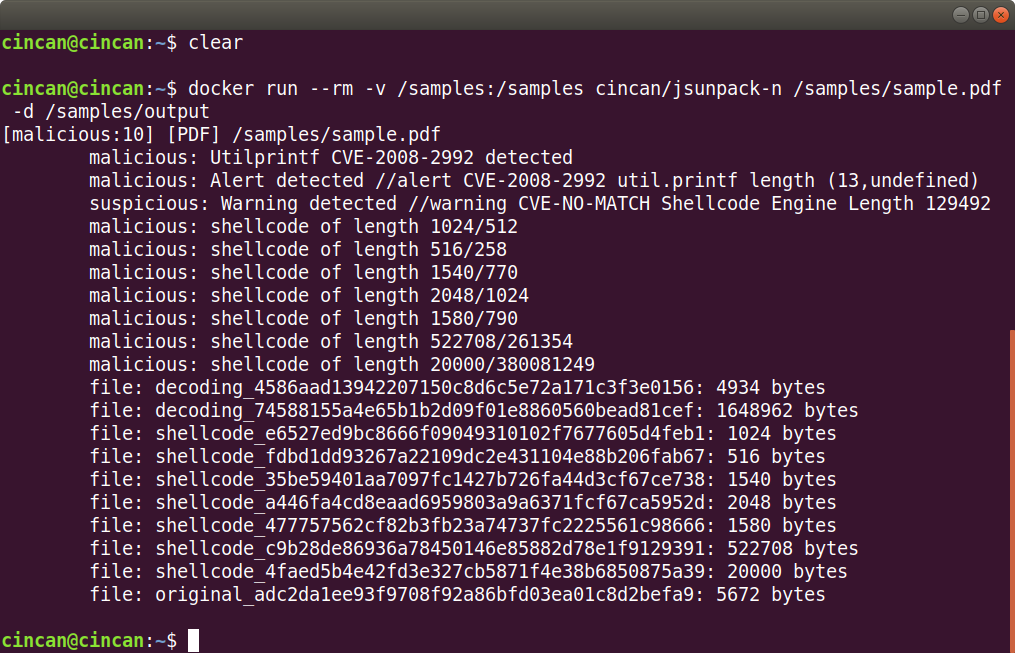
Jsunpack-n warns about the util.printf as well, but it also finds shellcode, which it automatically extracts into separate files in the output folder. The first file generated by jsunpack-n (decoding_4586…) contains the full extracted JavaScript. We can see that there is shellcode assigned to a variable within the JavaScript, and that it is in unicode format:
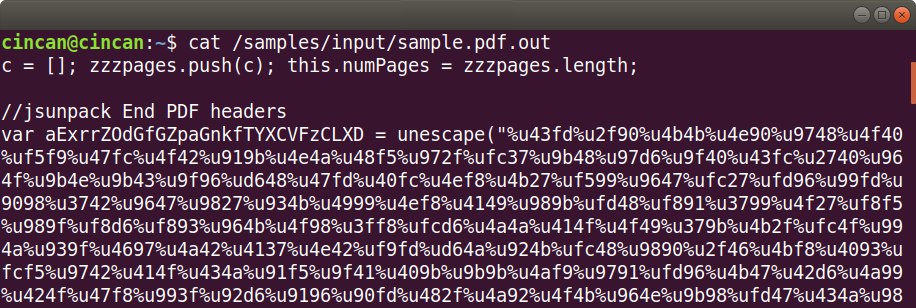
The unescape function translates the unicode to binary. The first shellcode file (shellcode_e6527…) generated by jsunpack-n contains the above seen shellcode in binary format, which makes it easier to analyse.
Peepdf
Peepdf is another great tool for PDF analysis. With PyV8 and Pylibemu installed you can also use it to analyse JavaScript and shellcode. Peepdf has an interactive mode, enabling efficient analysis of PDF objects. Sctest command in peepdf’s interactive mode is a great tool for investigating shellcode. Sctest emulates shellcode execution using Pylibemu. We can now run sctest analysis to the shellcode binary extracted by jsunpack-n. First, let’s run the cincan/peepdf container in interactive mode:
$ docker run --rm -v /samples:/samples -ti cincan/peepdf -i
And now we can analyse the shellcode binary with sctest:
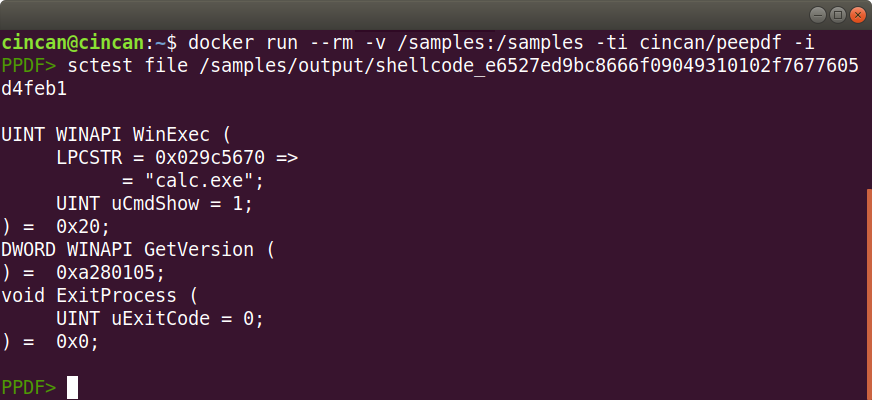
And here we can see, that the shellcode launches an executable file.
Shellcode2exe
Another way to analyse shellcode, is to extract the shellcode part from the JavaScript into an ASCII file, and convert it into a binary file using a python script called shellcode2exe.py, from Mario Vilas’s Shellcode Tools. Let’s say we have the code in a file called sample-code, so we can run the cincan/shellcode2exe image, and what we get is sample-code.exe file. As the shellcode is in unicode format, we need to use the -u option:
$ docker run --rm -v /samples:/samples cincan/shellcode2exe -u /samples/input/sample-code
PDFID malware recognition test
We also ran batch scans with PDFID just to see how well it performs at recognizing malicious PDF documents. The test environment included 8999 clean and 10980 malicious documents, and here are the results:
| Likely malicious | Likely clean | Requires more analysis | |
|---|---|---|---|
| Malware samples (10980) | 10972 | 0 | 8 |
| Clean samples (8999) | 3649 | 3612 | 1738 |
From this chart we can see, that PDFID quite perfectly identifies malware as malware: not a single malicious document is announced clean. On the other hand, only 40% of the clean files are identified as clean, but this doesn’t tell as much of the performance of PDFID, but of the complexity of malware recognition.
Summary
There are many approaches to a PDF analysis. This tutorial shows a few selected tools that are already available at the CinCan project Docker hub. All tools are downloadable at hub.docker.com/u/cincan.
To learn more about the project, you can see the project web site cincan.io, project Gitlab page gitlab.com/CinCan, or read our other blog posts.
 |
Vesa VertainenProject Engineer at JYVSECTEC Institute of Information Technology, JAMK University of Applied Sciences |